

How to quickly build and deploy adaptive edge vision applications with a production-ready platform
“The use of artificial intelligence (AI) on edge-based smart cameras is rapidly gaining acceptance in a growing number of embedded vision applications such as machine vision, security, retail, and robotics. While the rapid availability of available machine learning (ML) algorithms has helped usher in this interest in AI, developers still struggle to meet tight project timelines while keeping power consumption low for edge-based AI. applications provide high performance.
“
The use of artificial intelligence (AI) on edge-based smart cameras is rapidly gaining acceptance in a growing number of embedded vision applications such as machine vision, security, retail, and robotics. While the rapid availability of available machine learning (ML) algorithms has helped usher in this interest in AI, developers still struggle to meet tight project timelines while keeping power consumption low for edge-based AI. applications provide high performance.
To complicate matters, even newly deployed solutions can quickly become suboptimal due to rapid changes in application requirements and continuous improvement of evolutionary algorithms.
This article will introduce Xilinx’s flexible system-on-module (SOM) solution that developers can use to quickly implement edge-deployed smart camera solutions. The paper shows how they can more easily adapt these solutions to changing requirements without compromising critical requirements for latency and power consumption.
Accelerate the execution of vision applications
Xilinx’s Kria K26 SOM, based on a custom Zynq UltraScale+ multiprocessor system-on-chip (MPSoC), provides a powerful embedded processing system that includes a 64-bit quad-core Arm Cortex-A53 application processing unit (APU), a 32-bit dual-core Arm® Cortex®-R5F real-time processing unit (RPU) and an Arm Mali-400MP2 3D graphics processing unit (GPU). SOM combines MPSoC with four gigabytes of 64-bit wide double data rate 4 (DDR4) memory and associated memory controller and multiple non-volatile memory (NVM) devices including 512 megabits (Mb) of quad serial peripheral interface (QSPI) memory, 16 gigabytes (GB) of embedded multimedia card (eMMC) memory, and 64 kilobits (Kb) of electrically erasable programmable read-only memory (EEPROM) (figure 1).
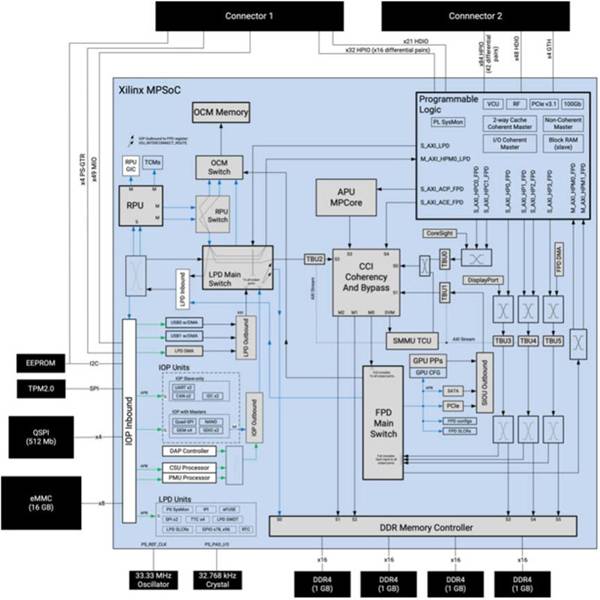
Figure 1: Xilinx’s Kria K26 SOM combines the extensive processing power of a custom Zynq UltraScale+ MPSoC with Trusted Platform Module 2.0 (TPM2) and dynamic and nonvolatile memory. (Image credit: Xilinx)
Xilinx complements its processing and memory assets with an extensive programmable logic system consisting of 256K system logic cells, 234K configurable logic block (CLB) flip-flops, 117K CLB look-up tables (LUTs), and distributed random access memory ( RAM), block RAM, and ultraRAM blocks totaling 26.6 megabits (Mb) of memory. In addition, the programmable logic system includes 1,248 digital signal processing (DSP) chips, four transceivers, and an H.264 and H.265 video codec capable of supporting up to 32 streams of simultaneous encoding/decoding, in 3840 x 2160 total pixels at 60 frames per second (fps). The SOM’s two 240-pin connectors provide ready access to function blocks and peripherals through user-configurable input/output (I/O).
This combination of processor cores, memory, and programmable logic provides a unique level of flexibility and performance that overcomes the major drawbacks of GPUs for high-speed execution of ML algorithms. Unlike the GPU’s fixed data flow, developers can reconfigure the K26 SOM datapath to optimize throughput and reduce latency. Additionally, the architecture of the K26 SOM is particularly well suited for sparse networks at the heart of an ever-increasing number of ML applications.
The programmability of the K26 SOM also addresses memory bottlenecks that both increase power consumption and limit the performance of memory-intensive applications such as ML built using traditional architectures of GPUs, multi-core processors and even advanced SoCs. In any application designed using these legacy devices, external memory typically accounts for about 40% of system power consumption, while the processor core and internal memory typically account for about 30% each. In contrast, developers can take advantage of the K26 SOM’s internal memory block and reconfigurability to implement designs that require little external memory access. As a result, performance is improved and power consumption is reduced compared to conventional devices (Figure 2).
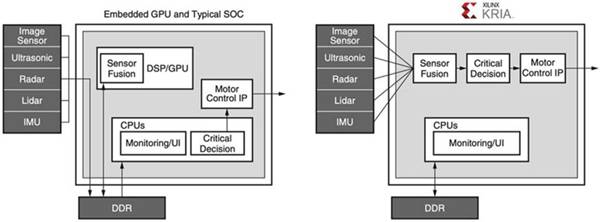
Figure 2: While embedded CPU and typical SoC-based systems require multiple, power-hungry accesses to memory to run their applications, Xilinx Kria-based systems employ an efficient vision pipeline that can be designed to avoid any DDR accesses. (Image credit: Xilinx)
In addition to high performance, low power consumption and extensive reconfigurability, the K26 SOM helps secure smart camera designs for sensitive applications. In addition to the SOM’s built-in TPM security device, MPSoC integrates a dedicated Configuration Security Unit (CSU) that supports secure boot, tamper monitoring, secure key storage, and cryptographic hardware acceleration. Together, the CSU, internal on-chip memory (OCM), and secure key storage provide the security foundation to ensure a hardware root of trust for secure boot and a trusted platform for application execution.
The extensive capabilities of the K26 SOM provide a strong foundation for implementing demanding edge-based applications. However, each application has its own requirements, i.e. the features and functions associated with a set of application-specific peripherals and other components. To simplify the implementation of application-specific solutions, the K26 SOM can be specifically inserted into a carrier card capable of carrying additional peripherals. Xilinx demonstrates this approach with its Kria K26-based KV260 Vision AI Starter Kit.
Starter Kit Simplifies Vision Application Development
Xilinx’s KV260 Vision AI Starter Kit includes a K26 SOM that plugs into a vision-centric carrier board, providing an out-of-the-box platform designed for instant evaluation and rapid development of intelligent vision applications. While the K26 SOM provides the required processing power, the starter kit’s carrier board provides power management, including power-up and reset sequencing, as well as interface options and connectors for cameras, displays, and microSD cards (Figure 3).
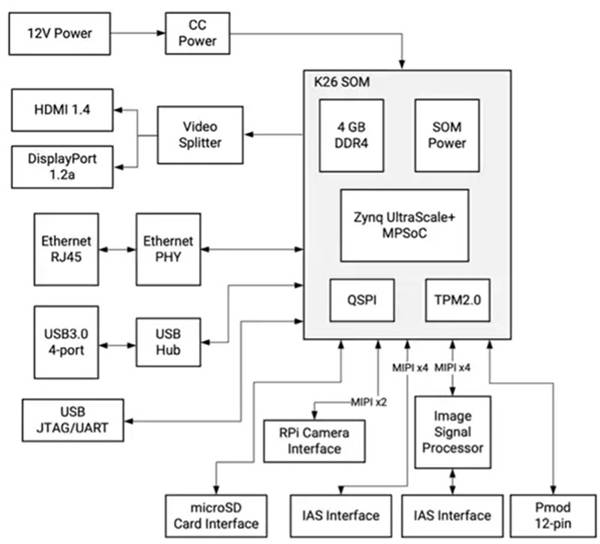
Figure 3: Xilinx’s KV260 Vision AI Starter Kit provides a complete smart vision solution using the K26 SOM plugged into a vision-centric carrier board. (Image credit: Xilinx)
In addition to multiple interfaces, the carrier board provides multi-camera support via its Raspberry Pi connector and a pair of Image Access System (IAS) connectors. One of the connectors links to a dedicated onsemi 13-megapixel AP1302 Image Sensor Processor (ISP), which handles all image processing functions.
To further accelerate the implementation of vision-based applications, Xilinx supports this predefined vision hardware platform with a variety of pre-built accelerated vision applications and a comprehensive set of software tools and libraries for custom development.
Accelerates applications to provide instant solutions
For immediate evaluation and rapid development of accelerated vision applications, Xilinx provides several pre-built applications that demonstrate the execution of several popular use cases, including smart camera face detection, pedestrian recognition and tracking, defect detection, and Pairwise keyword recognition for processing systems using MPSoC. In the Xilinx Kria App Store, each app provides a complete solution for its specific use case, complete with corresponding tools and resources. For example, a smart camera face detection application uses the KV260 carrier card’s built-in AR1335 image sensor and AP1302 ISP to capture images and render the results from the carrier card’s HDMI or DisplayPort (DP) output. For face detection processing, the application is configured with a K26 SOM to provide a vision pipeline accelerator and a pre-built machine learning inference engine for face detection, people counting, and other smart camera applications (Figure 4).
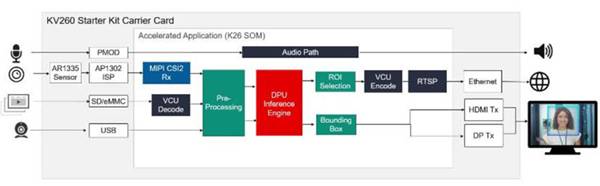
Figure 4: Pre-built acceleration applications can be downloaded from the Xilinx Kria app store and run immediately on the KV260 starter kit, providing a complete solution for vision usage models such as face detection. (Image credit: Xilinx)
Pre-built accelerated apps from the Xilinx App Store provide full implementation and support, allowing developers to get designs up and running in under an hour, even with little FPGA experience. When evaluating applications, they can use the provided software stack to modify functionality to explore alternative solutions. For broader custom development, Xilinx provides a comprehensive set of development tools and libraries.
AI Development Environments and Tools to Accelerate Custom Development
For custom development of AI-based applications, Xilinx’s Vitis AI development environment provides optimized tools, libraries, and pre-trained models that can be used as the basis for more specialized custom models. For the runtime operating environment, Xilinx’s Yocto-based PetaLinux Embedded Linux Software Development Kit (SDK) provides the full set of functionality needed to build, develop, test, and deploy embedded Linux systems.
Designed for experts and developers without FPGA experience, the Vitis AI environment abstracts the details of the underlying silicon hardware, allowing developers to focus on building more efficient ML models. In fact, the Vitis AI environment integrates with the open-source Apache Tensor Virtual Machine (TVM) deep learning compiler stack, enabling developers to compile their models from different frameworks to processors, GPUs or accelerators. Developers using Vitis AI with TVM can enhance their existing designs with accelerated vision capabilities, offloading computationally intensive vision workloads such as deep learning models to the Kria SOM. To help developers further optimize their deep learning models, Xilinx’s AI optimization tools can prune neural networks to reduce complexity in billion operations per second (Gops), increase frames per second (fps), and reduce Overparameterized models, where the model is compressed by up to 50 times, with little or no effect on the accuracy represented by mean precision (mAP) (Figure 5).
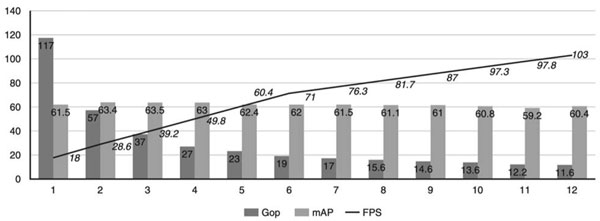
Figure 5: A case study from Xilinx Research shows that with a few iterations of pruning using the Xilinx AI optimization tool, it is possible to quickly reduce the complexity of the neural network in Gops count while improving frames per second, all of which have an impact on accuracy Almost no effect. (Image credit: Xilinx)
For the implementation of custom vision applications, Xilinx’s open source Vitis Vision library is optimized for high performance and low resource utilization on the Xilinx platform, providing a familiar OpenCV-based interface. On the analytics side, Xilinx’s Video Analytics SDK application framework helps developers build more efficient vision and video analytics pipelines without requiring deep FPGA knowledge. The Video Analytics SDK is based on the widely adopted open source GStreamer framework, which allows developers to quickly create custom acceleration kernels that integrate into the SDK framework as GStreamer plugins.
Typical embedded developers use these tools to easily assemble custom acceleration pipelines with or without custom acceleration cores.
Summarize
Compute-intensive ML algorithms enable intelligent vision technologies to be used in a variety of applications running at the edge, but developers face multiple challenges to meet the high performance, low power, and adaptability requirements of edge-based vision systems. Xilinx’s Kria K26 SOM solution provides the hardware foundation for accelerating advanced algorithms while staying within tight power budgets. Using the Kria K26-based starter kit and pre-built applications, developers can start evaluating smart vision applications immediately and use a comprehensive development environment to create custom edge device solutions.
The Links: LQ10D36A 2MBI200S-120-02


