Detailed explanation of machine learning steps, one article to understand the whole process!
“The process of deploying machine learning involves multiple steps. First choose a model, train it on a specific task, validate it with test data, then deploy the model to a real system and monitor it. In this article, we will discuss these steps, breaking down each step to introduce machine learning.
“
Author: M. Tim Jones
introduction
The process of deploying machine learning involves multiple steps. First choose a model, train it on a specific task, validate it with test data, then deploy the model to a real system and monitor it. In this article, we will discuss these steps, breaking down each step to introduce machine learning.
Machine learning refers to systems that can learn and improve without explicit instructions. These systems learn from data and are used to perform specific tasks or functions. In some cases, learning, or more specifically, training, occurs in a supervised fashion, where the model is adjusted to produce the correct output when the output is incorrect. In other cases, unsupervised learning is practiced, with the system combing through the data to discover previously unknown patterns. Most machine learning models follow both paradigms (supervised versus unsupervised learning).
Now, let’s dive into what we mean by “model” and explore how data can be the fuel for machine learning.
machine learning model
A model is an abstract representation of a machine learning solution. The model defines the architecture, and the architecture is trained to become a product implementation. So, instead of deploying a model, we deploy an implementation of the model trained on the data (more on that in the next section). Model + data + training = an instance of a machine learning solution (Figure 1).
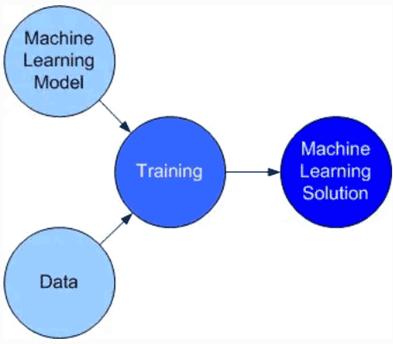
Figure 1: From machine learning model to solution. (Source: Author)
A machine learning solution represents a system. They take input, perform different types of computations in the network, and then provide output. Inputs and outputs represent numeric data, which means that, in some cases, translation is required. For example, feeding textual data into a deep learning network requires encoding words into numerical form, which is often a high-dimensional vector given the variety of words that can be used. Likewise, the output may need to be translated from numerical form back to textual form.
There are many types of machine learning models, such as neural network models, Bayesian models, regression models, clustering models, etc. The model you choose is based on the problem you set out to solve.
For neural networks, models range from shallow multilayer networks to deep neural networks, which also include multiple layers of specialized neurons (processing units). There are also a range of available models for deep neural networks based on the target application. For example:
If your application focuses on recognizing objects in images, a convolutional neural network (CNN) is an ideal model. CNNs have been applied to skin cancer detection and outperformed the average dermatologist.
If your application involves predicting or generating complex sequences such as human language sentences, then a recurrent neural network (RNN) or long short-term memory network (LSTM) are ideal models. LSTMs have also been applied to machine translation of human languages.
If your application involves describing image content in human language, you can use a combination of CNN and LSTM (the image is fed into the CNN, the output of the CNN represents the input of the LSTM, which emits a sequence of words).
Generative Adversarial Networks (GANs) are state-of-the-art models if your application involves generating realistic images, such as landscapes or human faces.
These models represent some of the deep neural network architectures commonly used today. Deep neural networks are popular because they can accept unstructured data such as images, video or audio information. The layers in the network form a feature hierarchy that enables them to classify very complex information. Deep neural networks have demonstrated state-of-the-art performance in many problem domains. But like other machine learning models, their accuracy relies on data. Next we will discuss this aspect.
data and training
Data is the fuel that drives machine learning, both in computation and in building machine learning solutions through model training. For training data for deep neural networks, it is critical to explore the necessary data in terms of both quantity and quality.
Deep neural networks require a lot of data to train; as a rule of thumb, 1,000 images per class are required for image classification. But the exact answer obviously depends on the complexity and fault tolerance of the model. Some examples in real machine learning solutions show that datasets come in various sizes. A face detection and recognition system needs 450,000 images, and a question-and-answer chatbot needs to be trained on 200,000 questions and 2 million matching answers. Depending on the problem to be solved, sometimes a smaller dataset is sufficient. A sentiment analysis solution (determining the polarity of opinions based on written text) requires only tens of thousands of samples.
The quality and quantity of data are equally important. Given that training requires large datasets, even a small amount of bad training data can lead to poor solutions. Depending on the type of data required, the data may go through a cleaning process. This process ensures that the dataset is consistent, free of duplicate data, and accurate and complete (no invalid or incomplete data). There are tools that can support this process. It is also important to validate the bias of the data to ensure that the data does not lead to biased machine learning solutions.
Machine learning training operates on numerical data, so depending on your solution, preprocessing steps may be required. For example, if the data is in human language, it must first be translated into digital form before it can be processed. Images can be preprocessed for consistency. For example, images fed into deep neural networks need to be resized and smoothed to remove noise, among other operations.
One of the biggest problems in machine learning is getting a dataset to train a machine learning solution. Depending on your specific problem, this can be quite a lot of work, as data may not be available and you need to find another way to get it.
Finally, the dataset should be split and used as training data and test data separately. The training data is used to train the model, and after the training is complete, the test data is used to verify the accuracy of the solution (Figure 2).
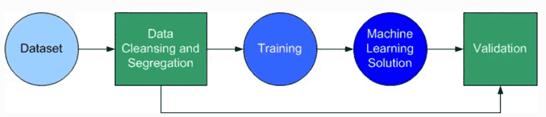
Figure 2: Split dataset for training and validation separately. (Source: Author)
There are tools to help with this process, and most frameworks have a “split” function for splitting training and testing data. Now let’s look at some frameworks that simplify the construction of machine learning solutions.
frame
Now, it is no longer necessary to build machine learning models from scratch. You can use frameworks that include these models and other tools to prepare data and validate your solutions. These frameworks also provide an environment for deploying solutions. Which framework to choose usually depends on your level of familiarity, but choose a framework that fits the application and model you want to use in the beginning.
TensorFlow is the best deep learning framework. It supports all popular models (CNN, RNN, LSTM, etc.) and allows you to develop in Python or C++. TensorFlow solutions can be deployed from high-end servers to mobile devices. If you’re just getting started, TensorFlow is a good place to start, with tutorials and extensive documentation.
CAFFE started out as an academic project, but after being released to open source, it has grown into a popular deep learning framework. CAFFE is written in C++, but also supports model development in Python. Like TensorFlow, it supports a wide range of deep learning models.
in the framework of PyTorch. PyTorch is another great option based on the wealth of available information, including hands-on tutorials for building different types of solutions.
The R language and environment are popular tools for machine learning and data science. It’s an interactive tool that helps you prototype your solution step-by-step while viewing the results in stages. With Keras, an open-source neural network library, you can build CNNs and RNNs with minimal development investment.
Model review
Once the model is trained and meets accuracy requirements, it can be deployed into production systems. But at this point, the solution needs to be reviewed to ensure it meets the requirements. This is especially important given that decisions are made by models and how they affect people.
Some machine learning models are transparent and understandable (e.g. decision trees). But other models, such as deep neural networks, are considered “black boxes,” where decisions are made by millions of computations that cannot be explained by the model itself. Thus, periodic audits were once acceptable, but continuous audits are fast becoming the norm in these dark-box situations, as mistakes are inevitable. Once errors are found, this information can be used as data to adjust the model.
Another consideration is the life cycle of the solution. The model decays and the input data changes, resulting in changes in model performance. Therefore, it must be accepted that the solution will become weak over time, and the machine learning solution must continuously change as the world around it changes.
Summarize
To deploy a machine learning solution, we start with a problem and then consider possible solutions. The next step is to acquire the data, which, after being properly cleaned and segmented, can be used to train and validate the model using the machine learning framework. Not all frameworks are the same, you can choose and apply based on your model and experience. A machine learning solution is then deployed using the framework, and with proper auditing, the solution can operate in the real world using real-time data.
The Links: LM130SS1T579 BSM400GA120DN2