“Whether a car is an assisted driving car in the early 2020s, that is, a car with an intelligent subnet for infotainment, transmission and autonomous driver assistance systems (ADAS), or the future level 3 (Level 3) The demand for hardware acceleration of networked transportation systems for autonomous vehicles of and above (with minimal human assistance when driving in traffic) is growing rapidly.
“
Author: Achronix Semiconductor Corporation
Overview
Whether a car is an assisted driving car in the early 2020s, that is, a car with an intelligent subnet for infotainment, transmission and autonomous driver assistance systems (ADAS), or the future level 3 (Level 3) The demand for hardware acceleration of networked transportation systems for autonomous vehicles of and above (with minimal human assistance when driving in traffic) is growing rapidly. A few years ago, the most popular car smart models launched by Nvidia, Mobileye and other CPU-centric vendors all assumed a centralized car network, in which a set of multi-core RISC CPUs with enhanced DSP functions were managed. Dedicated subnet. Now, the focus is rapidly shifting to the intelligentization of distributed cars, including complex cameras with related vision systems, sensor sub-networks with sensor hub architectures from the Internet of Things world, as well as in-vehicle infotainment systems (IVI) and ADAS The additional sub-networks and the transmission system/power system sub-networks work together to realize the functions of autonomous vehicles.
Although Achronix predicts that the favorite architecture of traditional vehicles and autonomous vehicles in the future will be distributed architecture, but any kind of network needs more backup co-processing capabilities than the architecture that has been implemented so far. The expected distributed computing architecture in automotive networks will be heterogeneous, requiring hybrid computing resources ranging from network control to parallel object recognition using deep learning nodes. As a result, the current base number of CPUs in luxury assisted driving cars is as high as 100, but it may increase to several hundred CPUs in self-driving cars. The sensor hub will require backup image processing to achieve distortion and splicing effects; Ethernet requires IP for packet filtering/monitoring, and special bridges with traditional CAN and FlexRay networks. Using an integer number of CPUs and GPUs in the first-generation automotive architecture will migrate to highly specialized computing nodes that require programmable acceleration.

In order to optimize chip area and power efficiency, on future automotive platforms, compared to fixed-function SoCs or traditional FPGAs, Speedcore™ embedded FPGA (eFPGA) silicon intellectual property (IP) is integrated into SoCs to provide customer configurability Function, it is the best choice to realize fast switching co-processing. To learn more about the evolution of the process, please refer to the Achronix white paper (WP008): EFPGA acceleration in SoC-Understanding the Speedcore IP design flow.
Speedcore eFPGA IP’s unique role in heterogeneous automotive data processing
Speedcore eFPGA IP can be integrated into ASIC or SoC to provide customized programmable logic arrays. Customers specify their logic, memory and DSP resource requirements, and then Achronix configures Speedcore IP to meet their specific needs. Speedcore look-up tables (LUT), RAM modules and DSP64 modules can be combined like building blocks to create the best programmable logic array for any given application. Speedcore eFPGA IP offers unique advantages in automotive network integration, whether it is replacing an FPGA in an existing design or enhancing an ASIC.
Higher performance C An eFPGA is directly connected to the ASIC through a wide parallel interface (no I/O buffer), providing significantly higher throughput, with a delay of only single-digit clock cycles. Delay is very important when you need to respond in real time to rapidly changing traffic conditions.
Lower power consumption:
The power consumption of the programmable I/O circuit accounts for half of the total power consumption of an independent FPGA. An eFPGA is directly connected to the SoC, completely eliminating large programmable I/O buffers, thereby reducing power consumption.
The area of an eFPGA can be precisely customized according to the requirements of the final application, and the process technology can be adjusted to achieve a balance between performance and power consumption.
Lower system cost:
The chip footprint of an eFPGA is much smaller than an equivalent standalone FPGA. This is because the programmable I/O buffers, unused DSP and memory modules, and over-configured LUTs and registers are all removed.
With Speedcore custom modules, custom functions can be added as additional modules to the eFPGA logic array and added together with traditional LUT, RAM, and DSP building blocks. This efficient implementation greatly reduces the size and area of the chip core and minimizes power consumption. The overall result is that the system cost is greatly reduced. For more details, please refer to the Achronix white paper (WP009): Using Speedcore Custom Modules to Enhance eFPGA Functions.
Higher system reliability and yield-Integrating FPGA functions into ASICs can improve system-level signal integrity and eliminate the reliability and yield losses associated with installing a separate FPGA on the PCB.
ADAS-centric processing model
Since the fusion of multiple visual processing systems is considered to be the core of driving assistance and autonomous vehicles, advanced driver assistance systems (ADAS) will maintain a core position in future automotive architectures, even if they are considered as managers among managers The multi-core vision processor has also been partially replaced. Real-time image processing involving both DSP and integer-intensive tasks was originally considered to be a problem of extracting information from still cameras or video images to determine the type, position, and speed of objects. As designers prepare for autonomous vehicles, the role of ADAS processors has expanded to include the fusion of vision, infrared, ultrasonic, lidar (LIDAR), and radar images. In traditional SoC and coprocessor suites, image preprocessing is performed separately from the CPU, and must be connected to the CPU through one or more high-speed buses. Even if the bus delay of the ADAS architecture is improved, when the coprocessor is implemented in a separate chip, the delay will be paid. Therefore, combining the eFPGA IP with the CPU in the unified ADAS architecture to ensure rapid response to visual, infrared or radar alerts in rapidly changing traffic conditions is the most effective way that can be verified.
Integrating multiple sensor sources with an ADAS core provides an ideal application scenario where Speedcore IP and a CPU are embedded in parallel. Speedcore IP allows customers to embed a custom programmable logic array into a standardized ASIC platform with dedicated computing resources (see the figure below and see page 4). In practice, this integration can write data summarized from the image source into the cache of the CPU instead of writing to an independent SDRAM. Reducing the interruption of the CPU means more real-time response to objects in the moving car’s field of view.
Vision processors (usually 2D images from camera inputs, although more and more 3D images have been included) can rely on graphics processor research accumulated over the years in edge extraction, format conversion, color balance, and resolution changes. Some processor IP vendors, including Ceva and Synopsys, have also increased the value of convolutional neural networks in object classification and recognition. Represented by Nvidia, CPU vendors with experience in these two fields have tried to strike a balance between traditional CPU/GPU tasks and specific neural network pattern recognition engines. For the neural network sub-architecture in the automobile, it is moving from an early mature architecture that requires high-precision floating-point DSP to a self-training inference engine that can use low-precision DSP cores. The Speedcore DSP64 module provides a lot of overhead for the new deep learning architecture. A common understanding of the evolution of ADAS and visual processing is that real-time automotive situational awareness will never have an optimal centralized ADAS processor or SoC. There will always be unexpected collaborative processing and acceleration tasks added to the ADAS central core.
Two additional functions inherent in any ADAS processor are sensor fusion/central integration and network conversion. The former involves combining and correlating information from various sensors: sensors such as CMOS images, infrared, lidar, and emerging miniaturized radars. Network conversion refers to the interface between the backbone network of Ethernet and CSI-2, FlexRay, CAN and even earlier network protocols. Although an ADAS SoC in the future can indeed integrate a sensor hub or an Ethernet MAC, there will always be some emerging functions that are excellently provided by the peripheral logic outside the CPU. Since the sensors are aggregated and the network is interconnected within the chip before being input to the CPU, maintaining security by reducing exposed interfaces is a solution, while improving reliability through on-chip integration, for many such tasks will be Proved to be the best solution.
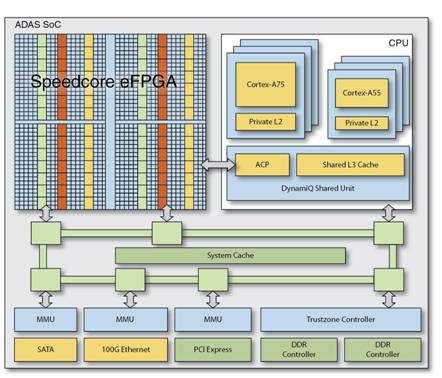
Figure 1: The Speedcore array (top left) is linked to the CPU subsystem and memory cluster
The role of programmability in functional safety
The transition from assisted driving vehicles to fully autonomous vehicles has increased the position of safety in new vehicles. The more the network controls the vehicles, the more drivers expect multiple levels of safety to prevent incidents such as the 2016 Tesla fatal accident that has caused high public concern. This drive for fault-tolerant safety has prompted the industry to promulgate the ISO 26262 standard for autonomous vehicles, which is a derivative standard of the IEC 61508 general functional safety standard for electrical and Electronic systems.
Early work in the EDA and SoC communities has achieved the standardization of the ISO 26262 method system to ensure functional safety in IP. Failure Mode, Effect, and Diagnostic Analysis (FMEDA) technology describes the standard specifications for the functions and failure modes of IP units, the impact of a failure mode on product functions, the ability to automatically diagnose and detect failures, the design strength, and the diversity of operating conditions, including the environment pressure. A robust system should maximize the diagnostic coverage of the IP unit and provide a high degree of functional safety by properly handling safe, detected and undetected faults.
Embedded FPGA can also enhance the safety of the vehicle as a system due to its extremely programmable characteristics. In addition to the “navigation” function of the master vehicle, the eFPGA in the SoC can also carry a large number of hardware diagnostic functions, and its operating speed is several orders of magnitude faster than software-based diagnostics, which greatly increases the coverage of any built-in self-test faults in the vehicle (BIST). In addition, they can programmatically help automakers update their deployed systems, thereby contributing to the ISO 26262 safety life cycle. Take the Tesla car accident as an example. If the root cause of the accident is an error in the object detection algorithm hosted in the hardware (for performance reasons), as long as a fix is developed, it can be pushed to the entire fleet. The long and expensive hardware development and redeployment process can be bypassed.
Distributed control means distributed intelligence
Due to the location of the camera and the demand for the local sensor hub, car designers always plan to adopt a large number of distributed intelligence in the car body. Nevertheless, early proponents of multi-core and multi-threaded processors such as Nvidia Tegra believe that most of the intelligence should be concentrated in or near the dashboard, although it is for the highly parallel CPU to work on object recognition. Now, advanced ADAS has attracted people’s attention to the blurred boundary between the full autonomy of assisted driving cars and three-level autonomous driving cars, returning to distributed intelligence, where CPU, GPU, and neural network processors are provided in the car body. Multiple management and control points. This shift means that more opportunities for programmable architectures exist outside of the SoC design with full coverage.
Now, the ADAS processor market is growing by more than 25% every year. This growth is due to the fact that ADAS functions have shifted from luxury vehicles to mid-sized and entry-level vehicles starting with functions such as automatic emergency braking, lane change assist, and adaptive cruise control-these functions will be commonly used by the middle of the next decade. At the same time, Level 3 autonomous vehicles will be launched on luxury platforms such as BMW 17 in 2018, while fully automated Level 5 cars may be available for commercial sale before 2022. As the autonomous driving platform develops from level three to level four and five, sensor hubs, cameras, and lidar/radar equipment will be distributed throughout the vehicle, and each will require local control.
This control mode has been clearly seen in the industry integration, such as Qualcomm’s acquisition of NXP and Intel’s acquisition of Mobileye. The processor field will be led by large suppliers who are committed to directing the development ecosystem to specific professional fields. Dominate-Intel uses a server plus machine learning model, Nvidia uses a GPU/machine learning model, and Qualcomm uses a cellular mobile communication-centric model, adding NXP Cognivue and i.MX processors. For example, IP developers such as Ceva, Cadence / Tensilica, Synopsys / ARC and VeriSilicon will try to subvert the closed mode through their expertise in special processor cores. At the same time, network experts such as Broadcom, Valens, and Marvell will seek to define automotive architectures around Ethernet backbone networks.
This market structure is somewhat similar to the era when enterprise networks evolved into data centers. Processor-centric semiconductor suppliers try to define a complete system architecture, but the design field shows a diverse Wild-West style, in which different logic kits are used for a component supplier (and OEM or car manufacturer) provide samples to create unique advantages. In such an environment, programmable logic configured as IP (such as Achronix’s Speedcore eFPGA) will play an important role, not only in the recent development of assisted driving and autonomous vehicles, but also in the development of these two types of vehicles over the years. The same goes for distributed processor development.
Speedcore eFPGA IP provides other advantages, such as minimizing CPU interrupts by writing to the CPU cache instead of off-chip memory. The BIST circuits required in CAN design usually account for 10% to 15% of the total ASIC circuits. Since the circuits supporting BIST can be programmed in the eFPGA, these circuits can be omitted in many cases. In addition, eFPGA can provide on-chip detection functions for diagnosis. For existing ASIC-based system designs that do not need to replace FPGAs, the flexibility of Speedcore IP will support the programming of new algorithms, thereby extending the service life of ASICs deployed in the field. Using Speedcore IP in existing designs of 5G cellular networks will also make this architecture an ideal choice for future V2X communication interfaces.
There are dozens or even hundreds of distributed CPUs in future fully automatic and advanced assisted driving vehicles. The peripheral processing functions used to connect the car subnets together can be served by ASICs, SoCs or traditional FPGAs. However, the introduction of Speedcore eFPGA IP provides advantages in latency, security, bandwidth, and reliability that traditional FPGAs do not have.
The Links: STK621-061 LM150X08-A4K1